Trudna sztuka cytowania (i tworzenia bibliografii)
System LaTeX posiada (może nie znakomite, ale całkiem niezłe) narzędzie do tworzenia bibliografii. Jest to system BibTeX.
Działa on w ten sposób, że tworzymy bazę danych zawierające wszelkie niezbędne informacje o publikacjach, a pisząc pracę odwołujemy się do rekordów tej bazy. Każdy rekord powinien posiadać swój unikatowy identyfikator służący do tworenia odwołań. Każdy rekord powinien zawierać minimalny, niezbędny zestaw informacji bibliograficznych. Zestaw ten jest różny dla różnych publikacji: inny dla artykułu, a inny dla książki. W najprostszym wypadku w tekście umieszczamy polecenie \cite{identyfikator_rekordu} i o sprawie ,,zapominamy’'.
Druga część systemu to mechanizm pozwalający podczas kompilacji dokumentu wyciągnąć z bazy danych informacje o cytowanych dokumentach i sformatować je zgdonie z wymaganym szablonem, a następnie wszystko połączyć w całość: w miejscu tekstu gdzie pojawiło się odwołanie do rekordu (\cite{identyfikator_rekordu}) pojawi się odpowiedni symbol cytowania (na przykład liczba w nawiasach kwadratowych: [123]), a w innym miejscu (na przykład na końcu dokumentu) pojawi się ułożona w zdefiniowanej kolejności (alfabetycznie, według nazwisk pierwszego autora, albo chronologicznie według dat publikacji, albo w kolejnosci cytowania w pracy) lista prac (oznaczonych odpowiednimi symbolami). Numerkami w nawiasach kwadratowych, na przykład. Co więcej bibliografia będzie sformatowana zgdonie z wymaganiami wydawcy (co, swoją drogą jest sporym problemem: dobrzy wydawcy dostarczają odpowiednie szablony, kiepscy mają jedynie wskazówki jak powinien wyglądać wpis dotyczący książki, artykułu, referatu konferencyjnego,… Wówczas Autor musi albo taki szablon stworzyć (nie zawsze jest to łatwe) albo wybrać taki, który jak najbardziej jest zgodny z oczekiwaniami wydawcy. To też nie jest łatwe.
Osobną kwestią jest wypełnienie bazy danych rekordami. Tak się składa, że system BibTeX jest jednym z niewielu standardów udostępniania informacji bibliograficznych powszechnie uznanych i stosowanych przez naukowców na całym świecie (choć niekoniecznie w Polsce). W związku z tym bardzo wielu wydawców i większość publikacyjnych baz danych oferuje metadane artykułów w tym formacie. Istnieją również narzędzia pozwalające na podstawie DOI odzyskanie metadanych w formacie BibTeXa (http://www.doi2bib.org/).
Najlepszą metodą tworzenia takiej bazy jest metoda ręczna: jak mamy w ręku oryginał tekstu, który chcemy w niej zachować, wpisujemy do bazy niezbędny zestaw informacji. Program JabRef podpowie, które pola są niezbędne. Nie jest to wielka praca, ale trzeba ją wykonać wtedy kiedy oryginał mamy w ręku.

Jest wreszcie informacja pozwalająca mająca, w zamierzeniu Autorów systemu, ułatwić zacytowanie artykułu. Klikamy w ,,Cytuj’’ i w następnym okienku znajdujemy możliwość uzyskania cytowania w formacie BibTeXa.

@inproceedings{freund1999alternating, title ={The alternating decision tree learning algorithm}, author ={Freund, Yoav and Mason, Llew}, booktitle={icml}, volume ={99}, pages ={124–133}, year ={1999} }
Bardzo wielu PT Twórców mając coś takiego wkleja odpowiedni rekord do swoje bazy danych. Wyszukiwarka jest wspaniała! Znalazła nam pożyteczny tekst, znalazła jego wersję elektroniczną i jeszcze oferuje metadane. A wszystko za darmo!
Problem pojawi się na znacznie późniejszym etapie, podczas formatowania bibliografii, gdyż jako tytuł książki w której ukazał się artykuł konferencyjny mamy podanie ,,icml’’, a cytowana praca objawia się tak:
[50] Y. Freund and L. Mason, ``The alternating decision tree learning algorithm,’’ in icml, Vol. 99, 1999, pp. 124–133.
I takie kursywiane icml przyciąga uwagę i, właściwie, nie pozwala na odnalezienie oryginału w sposób klasyczny (to znaczy nie korzystając z Internetu). Można, oczywiście, machnąć na to ręką: jak ktoś nie ma Internetu niech zajmie się czym innym niż pisaniem prac. Sam tytuł pozwala dosyć łatwo pracę odnaleźć (i wielu PT Autorów wychodzi z tego założenia dostarczając czasami tylko tytuł, albo tytuł i nazwisko jednego z twórców). W tym przypadku zaprotestowała Redakcja Techniczna czasopisma: zadając pytanie ,,To gdzie ta praca została opublikowana?’’ Ale Google Scholar podaje tylko ten wynik. Bo najlepszy, bo z tekstem źródłowym.
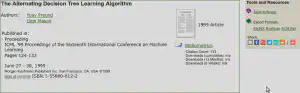
@inproceedings{Freund:1999:ADT:645528.657623, author = {Freund, Yoav and Mason, Llew}, title = {The Alternating Decision Tree Learning Algorithm}, booktitle = {Proceedings of the Sixteenth International Conference on Machine Learning}, series = {ICML ‘99}, year = {1999}, isbn = {1-55860-612-2}, pages = {124–133}, numpages = {10}, url = {http://dl.acm.org/citation.cfm?id=645528.657623}, acmid = {657623}, publisher = {Morgan Kaufmann Publishers Inc.}, address = {San Francisco, CA, USA}, }
I mamy już tytuł i wydawcę pracy.
Cóż zatem można radzić? Tworzenie Nauki powinno opierać się na korzystaniu ze źródeł ,,pierwotnych’’. I tego się trzymajmy.